Introduction
Data for science-based companies is of great value and has big potential for reuse. However, it often stays within the research project that generates it because it can be hard to find and interpret for people that were not involved. A FAIR data strategy is important to enhance your data value lifecycle. However, for data to be FAIR, it needs to be self-explaining. The employees in the use case described here recognized the value of their data, but felt they were falling short of realizing its full potential within the organization. In this article, we have a closer look at the challenges faced by one of our clients in the health and nutrition innovation sector.
Challenge
Combining data from different study types can lead to interesting new insights. In this use case, the client wanted to combine performance trial data with microbiome data to investigate any relationships in their response to specific treatments. To enable this, their data had to become more Findable, Accessible, Interoperable and Reusable (FAIR).
Approach
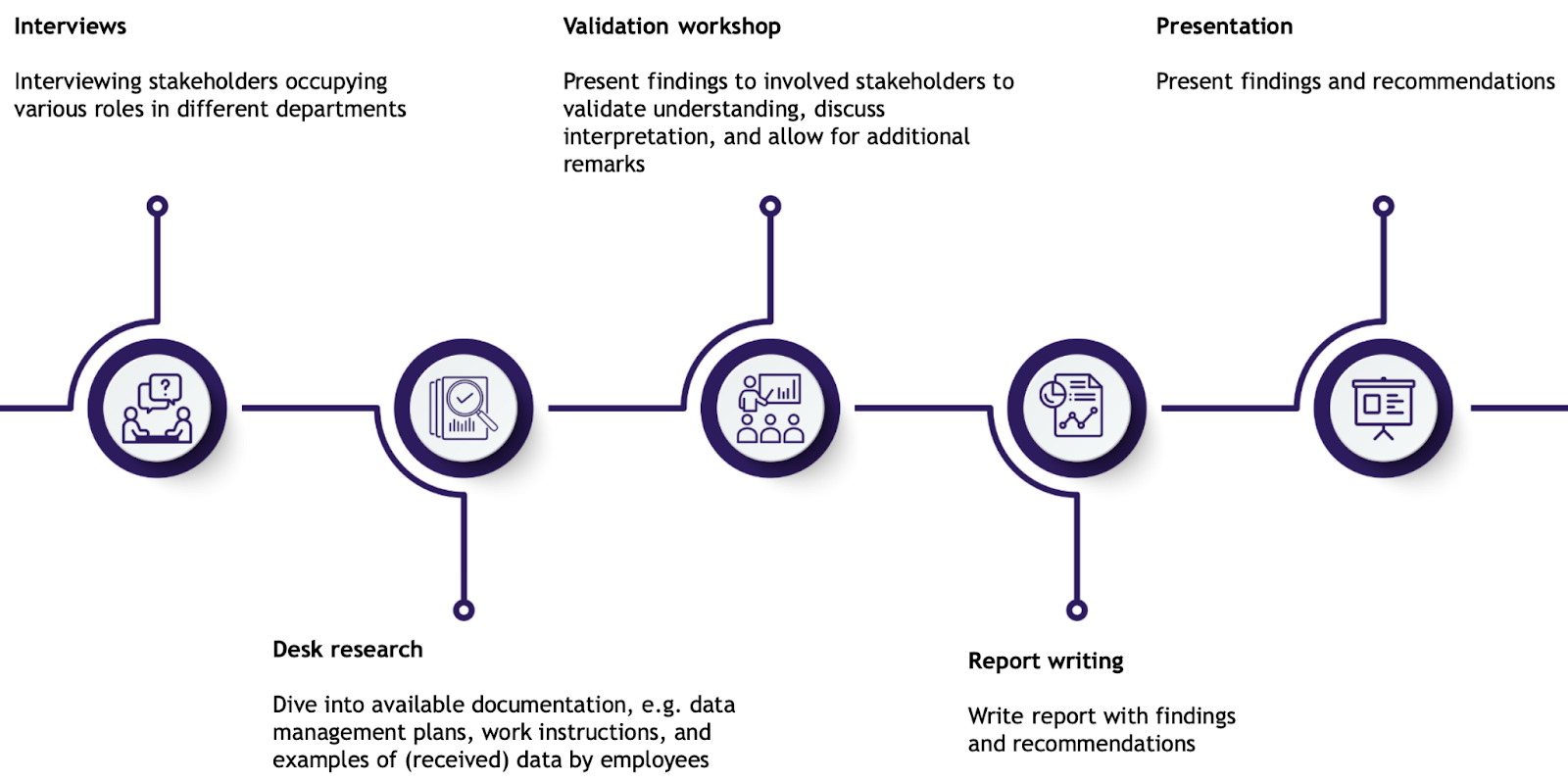
To understand how data for this specific client was generated, used and managed, a thorough data management analysis was performed. The approach for this process is visualized in Figure 1. It is tailored from the broader Data Landscape projects that The Hyve provides. Via interviews, stakeholders occupying various roles in different departments explained to our team all about their current data management practices and the challenges that they faced. Topics such as internal and external data sources, (meta)data storage systems, data reuse, access protocols, occurring data types, (meta)data formats, metadata templates, and vocabularies were touched.
Additionally, an ideal data flow was discussed and compared to the current situation. This ideal data flow was visualized and touched upon good data management practices in the three main phases of the client’s research: the project preparation phase, the trial/experiment phase, and the wrap-up phase. Any worries or questions about a possible implementation of this proposed ideal data flow were discussed during the interview and taken into account for the final recommendations. Besides the interviews, our team performed a deep-dive into the available documentation such as data management plans, work instructions, and examples of data that were either created or received by employees.
We presented our findings to all interviewed stakeholders to validate our understanding of their statements, discuss our interpretation of the situation, and allow the attendees to express any additional remarks and thoughts.
Outcome
Finally, an overview of the current state of data management and a set of recommendations on how to make this state more FAIR by Design were shared with the client via an in-depth report and presentation. The recommendations were explained in detail and prioritized by means of an impact-versus-effort estimation.
By addressing the challenges of data management efficiency and FAIRification, the client enhanced its understanding of how to improve the overall research capabilities towards a more future-proof FAIR by Design data architecture. With the provided recommendations, they can now plan the implementation of solutions that will optimize their data processes and lay the foundation for more impactful and collaborative scientific endeavors. This use case serves as a testament to the importance of proactive data management strategies in advancing scientific knowledge and innovation.
If you are looking to address your data management challenges and seek recommendations for cutting-edge software solutions and design implementations, The Hyve will be able to provide expert support from start to finish! Please reach out to us.